CHOOSING THE STATISTICAL METHOD
disampaikan pada workshop Pengolahan dan analisa data Penelitian Kesehatan
oleh H. Sastrawan, SKM, MHA
Setiap obervasi dapat dikelompokkan ke dalam empat jenis, yaitu Rasio, Interval, Ordinal, dan Nominal. Untuk memudahkan menghafal, tipe data dapat disingkat menjadi RION. Data berjenis rasio dan interval adalah data yang paling kuat/robust dan paling dianjurkan untuk digunakan.
Kesalahan penafsiran umumnya terjadi pada data bertipe Interval dan Ordinal. Tipe data interval seringkali dianggap data berjenis rasio. Namun demikian hal ini secara statistik tidak akan menjadi masalah karena baik data interval maupun data rasio dianalisa dengan metode yang sama, yaitu menggunakan statistik parametrik. Dengan demikian kesalahan penentuan tipe data interval dan rasio tidak secara teknik statistik tidak perlu diperdebatkan.
Kesalahan kedua adalah kesalahan penentuan skala data ordinal dan nominal. Kebanyakan orang hanya memahami bahwa data ordinal adalah data berjenjang, dimana ada tingkatan dari yang paling sedikit/paling rendah ke yang paling banyak/tinggi. Tidak sedikit buku statistik yang beredar di pasaran juga turut 'menyesatkan' pemahaman tersebut dengan tidak memberikan pemahaman yang lebih mendalam mengenai jenis data ordinal.
Untuk data yang sama (nilainya sama) urutannyapun sama. Hal ini dikenal dengan istilah "tie". Cara menghitung peringkat tie akan dibahas di artikel lainnya. (silahkan cek di waktu yang akan datang)
Nominal
Skala Nominal adalah skala yang paling lemah, tetapi paling praktis. Data berskala nominal umumnya didapat dengan cara 'menghitung' anggota kelompok tertentu. Nama lain dari skala ini adalah 'data hitung'.
Nama kelompok bukan hal penting. Yang penting adalah jumlah data yang ada di dalamnya.
Misalnya :
Jumlah mahasiswa laki - laki dan perempuan, jumlah mahasiswa berdasarkan agama, jumlah mahasiswa berdasarkan asal dst.
Bagian yang menarik adalah ketika nama kategori memiliki urutan tertentu seperti SD, SMP, SMA atau Tinggi, Sedang dan Rendah, dst.. Banyak orang bingung menghadapi situasi ini dimana mereka kemudian menyatakan datanya berskala ordinal, padahal sesungguhnya skalanya tetap nominal karena masih dalam katageri dan masih data hitung. Akan tetapi memang dikenal varian dari Nominal biasa yang disebut nominal berjenjang (ordered Nominal). Contohnya Tingkat pendidikan SD, SMP, SMA, PT dst, Tingkat Pengetahuan Tinggi, Sedang Rendah dst.
Untuk skala nominal dengan dua kategori saja dikenal dengan nama dikotomis, atau binary. Contohnya status pasien : Sehat dan Sakit, Hidup dan Mati, dst..
Pada prinsipnya setiap variabel dapat dikumpulkan dengan semua tipe data yang ada. Namun demikian disarankan untuk menggunakan tipe data Rasio dan Interval terlebih dahulu, baru menggunakan Ordinal dan Nominal jika tipe Rasio dan Interval tidak dapat digunakan (misalnya karena distribusi tidak normal atau asumsi randomisasi tidak terpenuhi, atau jumlah sampel terlalu kecil)
Perubahan dari tipe data satu ke tipe data lainnya mengandung resiko kehilangan informasi penting menyakngkut karakteristik data tersebut. PErhatikan ilustrasi berikut ini untuk menunjang pemahaman mengenai tipe data.
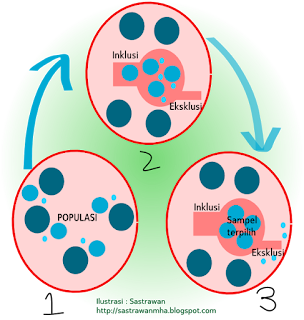
Tabel berikut ini adalah dari hasil penelitian (imajinatif) untuk mengukur tingkat pengetahuan mahasiswa tentang sesuatu dengan menggunakan berbagai skaala data.

Keterangan


Untuk melakukan uji perbandingan dua sampel dapat digunakan tabel berikut ini.

Cara Penggunaan :
Misalnya penelitian anda akan membandingkan kadar HB pada ibu hamil perokok dengan kadar HB ibu hamil bukan perokok, dimana Kadar HB diukur dengan menggunakan skala rasi. Uji Apa yang akan anda gunakan ?
Penyelesaian :
Dalam uji statistik tidak dibedakan antara skala rasio dan interval (diperlakukan sama) dengan demikian kita bisa melihat baris skala Interval dan Uji yang akan digunakan adalah antara lain :
Untuk mencari perbedaan baik pada satu ataupun pada dua kelompok sampel dapat menggunakan tabel berikut ini.

Cara Penggunaan: sama dengan di atas. Hanya saja tabel ini digunakan untuk menjawab pertanyaan : apakah ada perbedaan antara A dan B ?. Type data yang digunakan untuk pengukuran A dan B tersebut, serta jumlah sampel yang digunakan akan menentukan uji statistik yang digunakan
Selanjutnya untuk menguji hipotesa " Ada hubungan antara A dan B", dapat digunakan tabel bantuan berikut ini

Cara Penggunaan:
A dan B masing masing adalah variabel bebas dan terikat, yang diwakili oleh baris dan kolom yang di arsir. Misalnya Variabel A diukur dengan nominal, variabel B juga diukur dengan nominal, maka uji yang dapat dgunakan adalah Chi-Squared Test. ( Lihat kolom "Nominal" dan Baris "Nominal" pada tabel di atas lalu tarik garis ke bawah dan kesamping Pertemuannya adalah nama uji yang dapat digunakan.
Mudah Sekali bukan ?
Selamat Belajar. Jangan lupa meninggalkan komentar untuk artikel ini.
Penulis : H. Sastrawan, SKM, MHA
Dosen Metode Penelitian Kesehatan dan Biostatistik.
disampaikan pada workshop Pengolahan dan analisa data Penelitian Kesehatan
oleh H. Sastrawan, SKM, MHA
Objective :
- Peserta memahami type data /skala data yang digunakan dalam penelitian
- Peserta memahami metode analisa data untuk perbandingan dua sampel
- Peserta memahami metode analisa data untuk mencari perbedaan pada satu dan dua kelompok sampel
- Peserta memahami metode analisa data untuk mencari hubungan dua variabel
Evaluasi:
- Sebutkan Type atau skala data yang digunakan dalam penelitian.
- Sebutkan dan jelaskan type data yang paling baik/kuat untuk penelitian.
- Urutkan type data dari yang paling kuat/robust ke yang paling lemah.
- Jelaskan perbedaan antara data ordinal dan rasio.
- Jelaskan keunggulan dan kelemahan menggunakan skala data nominal
- Jelaskan skala data yang dapat digunakan untuk mengukur tingkat pengetahuan
- Jelaskan secara garis besar jenis analisa data yang biasa dilakukan dalam sebuah penelitan
- Jelaskan perbedaan antara 'satu kelompok data/sampel' dan 'dua kelompok data/sampel'
- Sebutkan uji yang digunakan untuk membandingkan denyut nadi sebelum dan sesudah melakukan olah raga.
- Uji apa yang akan anda gunakan untuk sebuah penelitian yang berjudul “Hubungan perilaku merokok pada orang tua dengan kejadian asma pada anak balita”. Jelaskan alasannya.
Materi :
Skala/Jenis Data :Setiap obervasi dapat dikelompokkan ke dalam empat jenis, yaitu Rasio, Interval, Ordinal, dan Nominal. Untuk memudahkan menghafal, tipe data dapat disingkat menjadi RION. Data berjenis rasio dan interval adalah data yang paling kuat/robust dan paling dianjurkan untuk digunakan.
Kesalahan penafsiran umumnya terjadi pada data bertipe Interval dan Ordinal. Tipe data interval seringkali dianggap data berjenis rasio. Namun demikian hal ini secara statistik tidak akan menjadi masalah karena baik data interval maupun data rasio dianalisa dengan metode yang sama, yaitu menggunakan statistik parametrik. Dengan demikian kesalahan penentuan tipe data interval dan rasio tidak secara teknik statistik tidak perlu diperdebatkan.
Kesalahan kedua adalah kesalahan penentuan skala data ordinal dan nominal. Kebanyakan orang hanya memahami bahwa data ordinal adalah data berjenjang, dimana ada tingkatan dari yang paling sedikit/paling rendah ke yang paling banyak/tinggi. Tidak sedikit buku statistik yang beredar di pasaran juga turut 'menyesatkan' pemahaman tersebut dengan tidak memberikan pemahaman yang lebih mendalam mengenai jenis data ordinal.
Rasio / Interval
Secara umum skala Rasio dan Interval ini didapat dari hasil pengukuran semua individu dalam sampel / populasi. Data jenis ini dikenal juga dengan nama data ukur. Pengukuran dapat dilakukan menggunakan alat ukur seperti timbangan/dacin, Microtois, Tensimeter, penggaris dll. Contoh data jenis ini adalah tinggi badan, berat badan, lingkar lengan, lingkar kepala, tekanan darah, denyut nadi, dll.
Untuk pengukuran sesuatu yang lebih abstrak dapat menggunakan alat ukur lain seperti quesioner. Contoh pengukuran abstrak adalah tingkat pengetahuan, IQ, EQ, dll.Ordinal
Kata kunci dari skala ordinal ini adalah 'ordered' atau terurut, yaitu datanya diurutkan dalam bentuk peringkat/rangking. Pemberian rangking bisa dengan cara ascending, atau descending. Artinya peneliti dapat memberikan peringkat 1 untuk yang terbaik, atau peringkat paling besar untuk yang terbaik, (misalnya peringkat 10 untuk yang terbaik dari 10 orang peserta). Yang pasti harus berurut.Untuk data yang sama (nilainya sama) urutannyapun sama. Hal ini dikenal dengan istilah "tie". Cara menghitung peringkat tie akan dibahas di artikel lainnya. (silahkan cek di waktu yang akan datang)
Nominal
Skala Nominal adalah skala yang paling lemah, tetapi paling praktis. Data berskala nominal umumnya didapat dengan cara 'menghitung' anggota kelompok tertentu. Nama lain dari skala ini adalah 'data hitung'.Nama kelompok bukan hal penting. Yang penting adalah jumlah data yang ada di dalamnya.
Misalnya :
Jumlah mahasiswa laki - laki dan perempuan, jumlah mahasiswa berdasarkan agama, jumlah mahasiswa berdasarkan asal dst.
Bagian yang menarik adalah ketika nama kategori memiliki urutan tertentu seperti SD, SMP, SMA atau Tinggi, Sedang dan Rendah, dst.. Banyak orang bingung menghadapi situasi ini dimana mereka kemudian menyatakan datanya berskala ordinal, padahal sesungguhnya skalanya tetap nominal karena masih dalam katageri dan masih data hitung. Akan tetapi memang dikenal varian dari Nominal biasa yang disebut nominal berjenjang (ordered Nominal). Contohnya Tingkat pendidikan SD, SMP, SMA, PT dst, Tingkat Pengetahuan Tinggi, Sedang Rendah dst.
Untuk skala nominal dengan dua kategori saja dikenal dengan nama dikotomis, atau binary. Contohnya status pasien : Sehat dan Sakit, Hidup dan Mati, dst..
Pada prinsipnya setiap variabel dapat dikumpulkan dengan semua tipe data yang ada. Namun demikian disarankan untuk menggunakan tipe data Rasio dan Interval terlebih dahulu, baru menggunakan Ordinal dan Nominal jika tipe Rasio dan Interval tidak dapat digunakan (misalnya karena distribusi tidak normal atau asumsi randomisasi tidak terpenuhi, atau jumlah sampel terlalu kecil)
Perubahan dari tipe data satu ke tipe data lainnya mengandung resiko kehilangan informasi penting menyakngkut karakteristik data tersebut. PErhatikan ilustrasi berikut ini untuk menunjang pemahaman mengenai tipe data.
Tabel berikut ini adalah dari hasil penelitian (imajinatif) untuk mengukur tingkat pengetahuan mahasiswa tentang sesuatu dengan menggunakan berbagai skaala data.
Keterangan
- Kolom kedua menunjukkan skor pengethuan dari hasil kuesioner (Interval)
- Kolom ketiga didapatkan dengan mengurutkan skor pada kolom kedua dan diberikan ranking (ordinal)
- Kolom keempat didapat dengan mengelompokkan kolom kedua ke dalam tiga kategori yaitu Tinggi, Sedang, dan Rendah (Nominal Berjenjang).
- Kolom terakhir adalah pengelompokan kolom kedua ke dalam dua kategori saja ( Binary/Dikotomi)
Data Rasio / Interval dibiarkan apa adanya, yaitu mengikuti hasil pengukuran individu (data ukur)
Data Ordinal memodifikasi data hasil pengukuran dengan memberi ranking
Selanjutnya untuk data Nominal dilakukan "Pengelompokan" terlebih dahulu, kemudian menghitung anggota tiap tiap kelompok tersebut sebagai berikut :
Memilih Uji Statistik
Setalah memahami konsep type data (RION), maka kini anda dengan mudah dapat menentukan uji statistik yang tepat untuk penelitian anda dengan menggunakan bantuan tabel berikut ini.Untuk melakukan uji perbandingan dua sampel dapat digunakan tabel berikut ini.
Cara Penggunaan :
Misalnya penelitian anda akan membandingkan kadar HB pada ibu hamil perokok dengan kadar HB ibu hamil bukan perokok, dimana Kadar HB diukur dengan menggunakan skala rasi. Uji Apa yang akan anda gunakan ?
Penyelesaian :
Dalam uji statistik tidak dibedakan antara skala rasio dan interval (diperlakukan sama) dengan demikian kita bisa melihat baris skala Interval dan Uji yang akan digunakan adalah antara lain :
- Normal Distribution for Means
- Two Sample T-Test
- Mann - Whitney U-Test
Untuk mencari perbedaan baik pada satu ataupun pada dua kelompok sampel dapat menggunakan tabel berikut ini.
Cara Penggunaan: sama dengan di atas. Hanya saja tabel ini digunakan untuk menjawab pertanyaan : apakah ada perbedaan antara A dan B ?. Type data yang digunakan untuk pengukuran A dan B tersebut, serta jumlah sampel yang digunakan akan menentukan uji statistik yang digunakan
Selanjutnya untuk menguji hipotesa " Ada hubungan antara A dan B", dapat digunakan tabel bantuan berikut ini
Cara Penggunaan:
A dan B masing masing adalah variabel bebas dan terikat, yang diwakili oleh baris dan kolom yang di arsir. Misalnya Variabel A diukur dengan nominal, variabel B juga diukur dengan nominal, maka uji yang dapat dgunakan adalah Chi-Squared Test. ( Lihat kolom "Nominal" dan Baris "Nominal" pada tabel di atas lalu tarik garis ke bawah dan kesamping Pertemuannya adalah nama uji yang dapat digunakan.
Mudah Sekali bukan ?
Selamat Belajar. Jangan lupa meninggalkan komentar untuk artikel ini.
Penulis : H. Sastrawan, SKM, MHA
Dosen Metode Penelitian Kesehatan dan Biostatistik.


{kind=link}
terima kasih infornya pak
BalasHapusmau diskusi pak..
berarti jika sy punya 1 var independen (skala interval), 1 dependen(rasio), 2 moderating (interval) saya bisa melakukan analisis pengaruhnya y pak? (karna interval n rasio diperlakukan sama)..
Skala Rasio dan Interval diperlakukan sama dalam analisa statistik. Untuk melakukan analisa pengaruh dengan beberapa variabel (bisa gabungan dari rasio, intrval, ordinal, dan nominal) anda bisa pertimbangkan untuk menggunakan regresi logistik. Sedangkan untuk uji dengan dua variabel (variabel lain sudah di kontrol) anda dapat memilih uji dari tabel 'relationship'. Yang penting adalah metodenya. Terima kasih.
Hapusterimakasih pak..
BalasHapusTerima kasih Tenri. Salam...
Hapusoh, iy pak... saya mau bertanya, untuk variabel bebas dan tergantung yang menggunakan data nominal, bisa tidak dianalisis pengaruhnya? kalau bisa, pakai teknik apa?
BalasHapusterimakasih.
Untuk skala nominal memang analisis pengaruh, hubungan, atau perbedaan menggunakan pendekatan yang sama. Yang berbeda adalah metode yang digunakan.
BalasHapusUntuk analisa biasanya digunakan cross tabulation (tabulasi silang) yang nantinya bisa mendapatkan angka chisquare, fisher exact, dll. Akan tetapi perlu diingat bahwa uji pengaruh dengan menggunakan data nominal metode yang kuat (misalnya true experiment, menggunakan case control, dan randomisasi), jika tidak hasilnya akan sangat lemah. Ingat analisa 'pengaruh' umumnya adalah kausatif, sedangkan analisa 'hubungan' umumnya asosiatif yang lebih mudah dilaksanakan.
mau bertanya lagi pak, kalau judul penelitiannya "pengaruh gaya belajar terhadap hasil belajar", analisis datanya pake apa pak?? teriakasih atas jawabannya.
HapusUntuk menentukan uji yang akan digunakan, harus ditentukan dulu skala / type data yang digunakan untuk pengukuran. Misalnya bagaimana cara mengukur gaya belajar (misalnya nominal - gaya belajar A - dan B) dan bagaimana cara mengukur hasil belajar (misalnya rasio/interval menggunakan IPK). Selanjutnya kita tinggal melihat perbedaan hasil belajar pada masing-masing kategori (bisa mengunakan uji beda) - lihat methods for comparing 2 samples. pilihannya bisa t-test, Mann-Whitney, atau uji distribusi mean tergantung jumlah sampel dan distribusi datanya. Sekali lagi jenis test ditentukan oleh skala data dan (untuk uji beda) juga tergantung berapa kategori..(Maksudnya metode belajar ada berapa - Kalau cuma dua bisa pakai yang disarankana tadi, kalau lebih, misalnya ada metode C dapat menggunakan uji lainnya sepert Anova.
Hapus;-)
Sangat membantu
BalasHapuspak mau tanya kalau skala data ordinal dan interval itu anlisis datanya pakai uji apa
BalasHapusJenis Uji akan ditentukan oleh tujuan penelitian, apakah akan membandingkan, mencari hubungan, atau mencari perbedaan. Selain itu uji juga ditentukan oleh apakah datanya berasal dari satu kelompok data atau lebih. Silahkan dilihat tabel yang ada di artikel ini. Terima kasih
HapusPak, mohon bantuannya. jika penelitian saya bertujuan untuk mencari pengaruh variabel x terhadap variabel y. namun sampel saya dibawah 30 orang. analisis data statistik apa yang semestinya saya gunakan, Pak? Mohon infonya, Pak. Terima kasih.
BalasHapusHai Nadela, Untuk menentukan uji statistik pastikan anda sudah mengetahui skala data yang akan digunakan baik pada variabel bebas (X) maupun pada variabel terikat (Y). Analisa pengaruh dapat menggunakan tabel analisa relationships atau bahkan pada kasus tertentu dapat juga menggunakan analisa diferences. Perbedaan antara 'pengaruh' dan 'hubungan' sebenarnya terletak pada desain penelitiannya (bukan pada uji statistiknya). Tentang jumlah sampel yang kecil.Sebenarnya jumlah sampel kecil tidak terlalu berpengaruh asalkan datanya berdistribusi normal. Hanya saja biasanya pada sampel kecil distribusinya jarang normal sehingga diperlukan faktor koreksi. Jika anda menggunakan SPSS biasanya akan ditampilkan berbagai variasi hasil dengan berbagai asumsi, misalnya distribusi normal/tidak normal sehingga anda hanya tinggal memilih salah satu dari sekian banyak pilihan hasil yang sudah disediakan di outout SPSS tersebut. (misalnya pada uji chisquare: biasanya ditampilkan hasil uji chisquare (normal) dan fisher exact (pada kasus dimana asumsi tidak terpenuhi). Terima kasih.
Hapusterima kasih infonya sisitematis dan bermanfaat
BalasHapusAssalamu'alaikum Mohon maaf pak, mohon bantuannya. hipotesis sy adalah kecemasan ibu hamil yang pada kelompok intervensi lebih rendah daripada kelompok kontrol. Saya pengennya pak jenis datanya rasio tetapi instrumen saya aslinya adalah ordinal. Mohon maaf pak, bagaimana solusinya? apakah bisa ordinal diubah ke rasio dan bagaimana caranya pak? (saya bingung pada definisi operasioanlnya pak). Terima kasih pak.
BalasHapusWaalaikum salam Nurfaizah,
HapusSkala rasio posisinya lebih tinggi dari skala ordinal. Penggantian skala (reduksi) hanya bisa dilakukan dari yang tinggi ke yang lebih rendah, jadi penurunan dari skala rasio menjadi ordinal masih bisa tapi tidak sebaliknya (tapi ini berlaku pada tahap setelah data dikumupulkan). Jika masih berbentuk instrumen tentunya anda bisa mengubah skala data pada instrument tersebut (selama memiliki dasar teori). Jika instrumen yang akan anda gunakan tersebut sudah paten (diambil dari buku teori atau jurnal penelitian yang berbobot), tentunya paling gampang adalah menggunakannya seperti apa adanya dan anda hanya perlu menyesuaikan uji statistiknya. Anda harus benar2 menguasai definisi operasional sebelum bisa membuat instrumen (atau menggunakan instrumen) secara benar. Semoga bermanfaat terima kasih.
Pak saya memiliki judul pengaruh penerapan Perda UU no.2 Tahun 2015 terhadap jumlah wajib pajak dan pendapatan wajib pajak reklame di dalam tenant mall kota malang. Uji apa yg hrs sy pergunakan? Bagaimana analisis datanya? Apakah benar hal tsb ada skala nominal dg menggunakan chi square? Mohon bantuan penjelasannya pak. Terima kasih
BalasHapusHi Theresia,
HapusPertanyaan besar yang harus anda pikirkan adalah " siapa /apa yang akan menjadi pembanding?" tanpa pembanding bagaimana kita bisa tahu ada atau tidaknya pengaruh Perda tersebut?. Pertanyaan ini perlu karena Perda pasti berlaku untuk semua tenant di kota Malang, sehingga sulit mendapat pembanding (yang tidak terkena dampak Perda). Alternatif lainnya bisa dengan membandingkan data sebelum dan sesudah perda di terapkan, atau membandingkan dengan kota lain yang tidak ada perdanya. Namun demikian, bagi saya, topik ini terlalu mudah untuk ditebak hasilnya apalagi jika perda tersebut memang mengatur tentang pajak. Topik ini mungkin akan lebih menantang jika perda tersebut mengatur sesuatu yang tidak terkait langsung dengan pajak dan wajib, sehingga memberikan ruang untuk penelitian. Pastinya terserah anda dan pembimbingnya untuk menilai apakah topik ini 'seksi' atau tidak. Mengenai uji statistik tergantung data apa yang dikumpulkan dan skala data apa yang akan digunakan (selengkapnya baca artikel ini). Semoga bermanfaat. Terima kasih
Pak, sya ingin brtanya dta mnakah yg hrus d input dlm variabel test pda uji t independent spss apkh dta post test sja atau dta yg mna pak? Lalu, apakh sdh sesuai seandainy sya menggunkn uji t independent trsbut dgn tjuan pnelitian sya yaitu mngetahui perbedaan efwktivitas perlakuan x1 dan perlqkuan x2 terhadap y? Dmna, dta berdiatribusi normal pre dan post, variansny sma dgn skala intrval. Atau adkh uji lain yng seharunya lbh sesuai dngn penelitian trsbut? Trmakasih dan mhon banuannya pak..
BalasHapusHai Ita, menggunakan SPSS untuk uji statistik itu sangat mudah. SPSS mengasumsikan anda memasukkan data dalam format tabel dengan baris dan kolom. Setiap kolom mewakili variabel anda. Misalnya, untuk kasus anda, kolom yang dibutuhkan minimal 2 kolom. Kolom 1 berisi 'penanda' atau 'grouping', misalnya kode a untuk perlakukan 1 dan kode b untuk perlakuan dua. Kolom 2 berisi data hasil pengukuran pada perlakuan tersebut. Data ini harus berskala rasio atau interval.
HapusKolom 2 ini akan menjadi 'test variable' anda di SPSS, sedangkan kolom 1 akan menjadi 'Grouping variable'
Semoga membantu.
Salam
Trmaksih ats pnjelasannya pak, dan sya sdh melksanaknny.., tp yang msh sya bingungkan, stlah sya prhatikan pda hasil akhir uji trsbut perlakuan x1 jadiny lbh baik dibandingkan x2 dikarenakan bilangan pd hasil x1 trsbut lbh tinggi drpda angka x2. Smntra sharusnya x2 dgn bilangan yg lbh kcil lah yg lbh baik pak.., karena pnelitian sya ttg pengurangan nyeri., jdi prlakuan x2 lah yg membrikan efek pengurangan nyeri lbh baik drpda x1.
HapusOleh karena tulh sya memastikan utk dta yg seharusny d input pda kolom 2 trsebut pak.., karena hasilny jdi dmikian pak..,trimaksih dan mohon bantuanny pak.
Pastikan Ita memasukkan data dengan benar. Jika sudah benar, apapun hasilnya itulah kesimpulan penelitiannya. Jangan takut kalau hasilnya tidak sesuai harapan karena salah satu alasan untuk menggunakan statistik adalah untuk memberikan penilaian objektif dan tentunya tidak selalu harus sesuai harapan. Good luck !
Hapusterimakasih pak infonya,
BalasHapussaya mau bertanya, apabila penelitian saya memiliki skala nominal (baik dan kurang baik) serta ordinal (rendah, sedang, tinggi) maka uji apa yang bisa saya gunakan?
kemudian saya pernah melihat penelitian sebelumnya dengan skala tersebut, kemudian menggunakan uji chi-square dan koefisien kontingency untuk melihat nilai r, apakah ada kriteria tertentu tidak pak apabila menggunakan 2 uji seperti itu,
kemudian bagaimana alurnya, untuk melakukan 2 uji tersebut
dan yang terakhir, koefisien kontingency itukan untuk melihat nilai r, akan tetapi disana ttp muncul nilai p, kemudian apa yang menjadi alasan penggunaan.uji chi square terlebih dahulu?
mohon.penjelasanya pak,.terimakasih 😊
Hi Melly,
HapusPertama, jika hanya ada dua pilihan (baik dan kurang baik) skala datanya biasanya disebut dikotomis, meskipun dikotomis sendiri adalah termasuk data nominal. Kedua, kategori rendah, sedang, dan tinggi, yang anda maksud disini kemungkinan besar bukan termasuk skala ordinal meskipun kata 'rendah','sedang', dan 'tinggi' memiliki makna berjenjang. Dalam hal ini, kata kata tersebut hanya digunakan untuk 'mengelompokkan' data sehingga lebih tepatnya disebut skala nominal juga. Oleh karenanya anda bisa menggunakan Uji Chi Square. (Ingat, uji ini hanya digunakan untuk skala nominal dan tidak bisa digunakan untuk skala ordinal). Kesalahan umum yang sering terjadi, bahkan dalam beberapa buku teks, menyebut kategori tinggi, sedang, rendah sebagai skala ordinal dan diteruskan dengan uji chisquare, padahal uji ini tidak mungkin digunakan untuk skala ordinal. Silahkan lihat penjelasan pada artikel ini.
Untuk uji menggunakan SPSS, atau software statistik lainnya, biasanya nilai p sudah cukup digunakan untuk pengambilan keputusan.
Semoga membantu. Terima kasih
Selamat siang pa' uji apa yang cocok untuk penelitian dengan skala ordinal adapun judulnya hubungan aktivifisik dengan gejala menopause dengan jumlah sampel 191
BalasHapusHalo mas Suherman, apakah kedua variable diukur dengan skala ordinal ? Jika ya anda bisa mempertimbangkan Mann-Whitney U Test. Jika tidak, silahkan lihat tabel 'Relationship' di atas. Semoga membantu, terima kasih
Hapusselamat malam bapak, saya mau tanya judul sy adalah "hub pendapatan orang tua trhd prkmbangan kognitif anak" nah disini saya menggunakan data interval seperti untuk perkembangan kognitif menggunakan lembar penilaian 1-10 apakah cara memasukkan nilai di spps nya juga 1-10 gitu ? terimakasih
BalasHapusUntuk SPSS, anda bisa mengentry data mentahnya, atau data yang sudah dikelompokkan. Jadi, ya.. silahkan masukkan datanya apa adanya
HapusAss pak.
BalasHapusSaya mau bertanya apakah tidak masalah menguji x ratio dgn y nominal. Mohon bantuannya pak.
Tidak ada
Hapusassalamualaikum pak, saya nisa. saya ingin bertanya. tugas akhir saya memakai metode regresi logistk multinomial dimana variabel tak bebas nya memiliki 3 kategori dan variabel bebas nya berupa data numerik (nilai UN), pertanyaan saya, untuk analisis bivariat, uji apa yang harus saya gunakan untuk melihat hubungan antara variabel bebas nominal 3 kategori dan variabel bebas berupa data numerik?
BalasHapusterima kasih sebelumnya pak
Waalaikum salam Nisa.
HapusTujuan menggunakan regresi logistik adalah untuk membuat 'model' atau 'formula' tentang interaksi dari variabel terkait dengan harapan akan membantu menghitung probablity kejadian variabel terikat jika kondisi pada variabel bebasnya diketahui. Dalam uji reglog, variabel 2 yang tidak significant akan secara otomatis (SPSS) dihitung dan harus dikeluarkan dari model. Langkah ini dilakukan secara berulang2 (oleh SPSS) sampai semua variabel significant dan dapat dimasukkan dalam model. Jika dapat dikerjakan otomatis, mengapa harus melakukan uji bivariat secara terpisah?. Uji yang dilakukan oleh reglog jauh lebih bagus karena menghitung effect variabel secara individu dan bersamaan.
selamat malam pak, mohon bantuannya, krna sya blom mngerti ttg statistik dan masih dalam proses belajar, sya mau tnya kalo judul "komunikasi interpersonal orang tua dan guru terhadap prestasi belajar siswa " apakah bisa dijadikan judul penelitian pak? itu termasuk 3 variabel? angket disebar kesiapa ajh pak? ap dlu yang harus di kerjakan, rumus apa, bagaimana penyelesaiannya pak, maaf ya pak,, mhon sekali bantuannya,, trimakasih pak sebelumnya
BalasHapusHalo selamat malam. Terima kasih sudah bertanya. mengenai bisa tidak menjadikan judul penelitian itu sangat bergantung komunikasi anda dengan dosen pembimbing. Bagi saya judul ini cukup lumayan. Saya mengasumsikan anda saat ini sedang menempuh pendidikan setara S1 dan Saran saya kalau bisa jangan meneliti yang melibatkan banyak variabel karena biasanya akan merepotkan Anda sendiri (Kecuali Anda ingin melakukan penelitian tersebut). ingat pada tahap ini anda berada pada tahap belajar melakukan penelitian dengan tujuan agar anda bisa memahami dasar-dasar penelitian. kembali ke Judul “ komunikasi interpersonal orang tua dan guru terhadap prestasi belajar siswa”. Saya rasa Anda cukup melihat dua variabel saja yaitu yang pertama variabel komunikasi interpersonal dan variabel kedua prestasi belajar. Anda harus menentukan apa yang dimaksud dengan komunikasi interpersonal, apakah komunikasi yang Anda maksud adalah frekuensi komunikasi orang tua dengan guru atau kualitas / materi komunikasi tersebut atau dua-duanya, atau yang lainnya. apapun yang anda pilih semuanya harus bisa diukur karena anda melakukan penelitian kuantitatif. untuk variabel kedua yaitu prestasi belajar siswa anda bisa mengukurnya dengan nilai raport atau indikator lainnya yang digunakan dalam dunia pendidikan. langkah berikutnya adalah anda menentukan skala apa yang akan anda gunakan untuk mengukur ke dua variabel. Angket tentu saja disebar kepada sampel dalam hal ini adalah guru atau orang tua atau kedua-duanya. Anda harus mendesain kuesioner sedemikian rupa untuk menjawab atau menjelaskan variabel yang anda teliti sekaligus agar memungkinkan anda untuk mengukurnya. mengenai rumus untuk uji statistik tergantung apa tujuan penelitian dan skala apa yang digunakan untuk tiap variabelnya (ratio - interval - ordinal - nominal). jika Anda belum jelas mengenai skala silakan Anda membaca artikel diatas. terima kasih
HapusPak, saya Irma mau bertanga
BalasHapusJika variabel saya adalah pengalaman, diukur bedasarkan lama tahun bekerja dan banyaknya kasus yg dialami setiap tahun
Jadi saya membuat tingkatan 1 untuk 0-3 tahun, 2 untuk 4-7 tahun, 3 untuk 8-11 tahun dan 4 untuk lebih dari 11 tahun...begitu juga dengan banyaknya kasus yg dialami 1 untuk 1 kasus, dst sampai dengan 4 untuk 4 kasus
Begitu juga dengan variabel tingkat pendidikan,,1 untuk s1, 2 untuk s2 dan 3 untuk s3
Nah, tingkatan tersebut apakah bisa dinamakan skala ordinal? Atau nominal?
Lalu 2 variabel bebas lainnya menggunakan skala likert
Dan Y berskala likert
Jika memang variabel pengalaman dan tingkat pendidikan tadi adalah skala ordinal, maka dapatkah saya langsung menguji regresi linear berganda
Karena asumsi saya tingkatannya sama dan saya belum menemukan referensi yg mengharuskan uji datanya
Melihat variabel Y saya berskala likert dan x1,x2 berskala likert namun x3,x4 berskala ordinal (jika itu dinamakan ordinal)
Mohon penjelasannya pak
Hai Irma, Terima kasih telah bertanya.
HapusSebetulnya informasi yang Irma berikan belum lengkap (terutama mengenai penelitian apa dan judulnya apa, variabel-variabelnya apa dst). Saya tahu Irma mengasumsikan semakin lama seseorang bekerja akan menjadi semakin berpengalaman - anda harus mensuport asumsi ini dengan evidence. Kalau tidak bisa menyediakan evidence, sebaiknya gunakan saja 'masa kerja / lama bekerja' sebagai variabel untuk menggantikan 'pengalaman'. Berikutnya, keputusan untuk mengunakan pengelompokan 0-3, 4- 7 dst itu harus ada dasar / tujuannya. Jadi tidak bisa ditentukan sembarangan. Saran saya, jika memang anda bisa memperoleh data berskala rasio, mengapa harus menggunakan skala yang lebih lemah?. Keputusan untuk menurunkan skala itu biasanya dilakukan setelah pengolahan data menggunakan skala tertinggi (rasio) tidak bisa dilakukan, misalnya karena datanya tidak berdistribusi normal. Kalaupun diputuskan sebelum tahap pengolahan data, itu biasanya karena teknik sampling yang digunakan tidak random (dipastikan datanya tidak akan memenuhi asumsi normalitas). Irma bisa menggunakan lama kerja dalam tahun atau bulan langsung sebagai skala rasio/interval, demikian juga dengan jumlah kasus (tidak perlu dikelompokkan lagi). Untuk tingkat pendidikan, anda bisa menggunakan skala ordinal atau nominal, tergantung tujuan / hipotesa penelitian. Ingat pada skala ordinal angka yang digunakan menunjukkan urutan (dari tinggi ke rendah atau sebaliknya). Pada skala nominal, tidak menunjukkan urutan (meskipun anda memberi label yang secara logika berurutan, misalnya label 'satu', 'dua', dst). Intinya, jika anda ingin melihat pengaruh dari urutan pendidikan itu, maka gunakan skala ordinal, jika hanya ingin melihat perbedaan pada masing-masing kelompok, gunakan skala nominal. Mengenai skala likert, skala likert itu sebenarnya didesain untuk pengukuran berskala ordinal. Tapi semuanya kembali ke tujuan dari penelitian dan bagaimana anda akan analisa dan menggunakan data. Terima kasih
Halo bapak.. saya lintang saya ingin bertanya: judul penelitian saya adalah "hubungan antara tipe kepribadian dengan resiliensi pada mahasiswa" dalam tipe kepribadian alat tes nya dengan skor 1=YA, 0=tidak dan nantinya akan ketemu apakah seseorang itu introvert dan ekstrovert. Apakah bener untuk tipe kepribadian itu merupakan data dikotomi? Selanjutnya untuk resiliensi menggunakan skala likert dimana skornya s=1 ss=2 ts=3 sts=4 dan sebaliknya. Nah untuk resiliensi merupakan data apa ya pak? Dan untuk uji statistiknya saya harus menggunakan uji apa bapak? Terimakasih
BalasHapusHalo Lintang Dewi,
HapusMaaf saya tidak membaca komentar di blog karena saya sedang sibuk di kampus. Karena dalam penelitian anda hanya ada dua pilihan untuk tipe keperibadian, maka itu sudah memenuhi kriteria untuk disebut dikotomi. Tetapi untuk valiable resilience, masih perlu penjelasan. Apakah anda nantinya akan menjumlahkan semua skor pada setiap sampel? Selanjutnya apakah setelah dijumlahkan, apakah sampel akan diurutkan berdasarkan jumlah (total) skor resilience. Jika jawaban untuk kedua pertanyaan ini 'iya' maka dapat dipastikan bahwa anda mengukur resilience dengan menggunakan skala ordinal. Alternatif lainnya adalah anda bisa menggunakan total skor itu tanpa mengurutkannya terlebih dahulu. Dalam hal ini skalanya lebih condong ke skala interval. Tapi keputusan menggunakan skala data dalam analisa harus melihat lagi asumsi pengambilan data (random atau tidak) dan apakah sebaran datanya normal atau tidak. Ini perlu dikonsultasikan sama pembimbingnya.
Penting diingat bahwa skala likert pada masing masing item pertanyaan memang adalah skala ordinal. Tapi yang dijadikan patokan dalam menentukan uji statistik adalah kategori kumulatif yang meliputi semua sampel (bukan per item pertanyaannya). Semoga membantu.